Hoy exploraremos las redes neuronales. ¿Alguna vez te has preguntado cómo estas maravillas tecnológicas aprenden y se adaptan? Vamos a desentrañar sus secretos, desde su definición básica hasta los distintos tipos que existen.
Historia de las redes neuronales
La historia de las redes comenzó en los años 50, con el perceptrón de Frank Rosenblatt. Inspirado en el cerebro humano, este modelo simple abrió la puerta a un universo de posibilidades. Luego, en los 60, el multilayer perceptron llevó las cosas un paso más allá, introduciendo múltiples capas y la idea de redes más complejas.

Pero fue en los 80 cuando todo cambió. La introducción de neuronas sigmoidales y el algoritmo de backpropagation transformaron las redes de simples modelos a sistemas capaces de aprender de manera autónoma. Esto marcó el inicio de lo que hoy conocemos como aprendizaje automático.
En los 90, las cosas se pusieron aún más interesantes. Los sistemas neuronales convolucionales, inspiradas en el cortex visual de los animales, revolucionaron el procesamiento de imágenes. Y con la llegada de las LSTM en 1997, las redes neuronales comenzaron a manejar tareas de memoria y secuencia, como el procesamiento del lenguaje.
Hoy, gracias a estas innovaciones, las inteligencia artificial redes neuronales están en el corazón de la inteligencia artificial, transformando todo, desde cómo interactuamos con la tecnología hasta cómo entendemos el mundo a nuestro alrededor.
¿Cómo funciona una red neuronal?
Las redes, esos fascinantes cerebros artificiales, se crearon de una manera que parece sacada de una novela de ciencia ficción al proceso de crear. Imagina un enjambre de neuronas, cada una interconectada con múltiples elementos, formando una red compleja. Cada neurona recibe señales y las procesa basándose en su ‘peso’, una especie de importancia asignada a cada conexión, y luego pasa la información procesada a la siguiente neurona.
Visualiza la estructura de la red, dividida en capas. La primera, la capa de entrada, recibe los datos brutos. Después, las capas ocultas, el verdadero núcleo del proceso, donde los datos se transforman y se interpretan. Finalmente, la capa de salida nos ofrece el resultado.
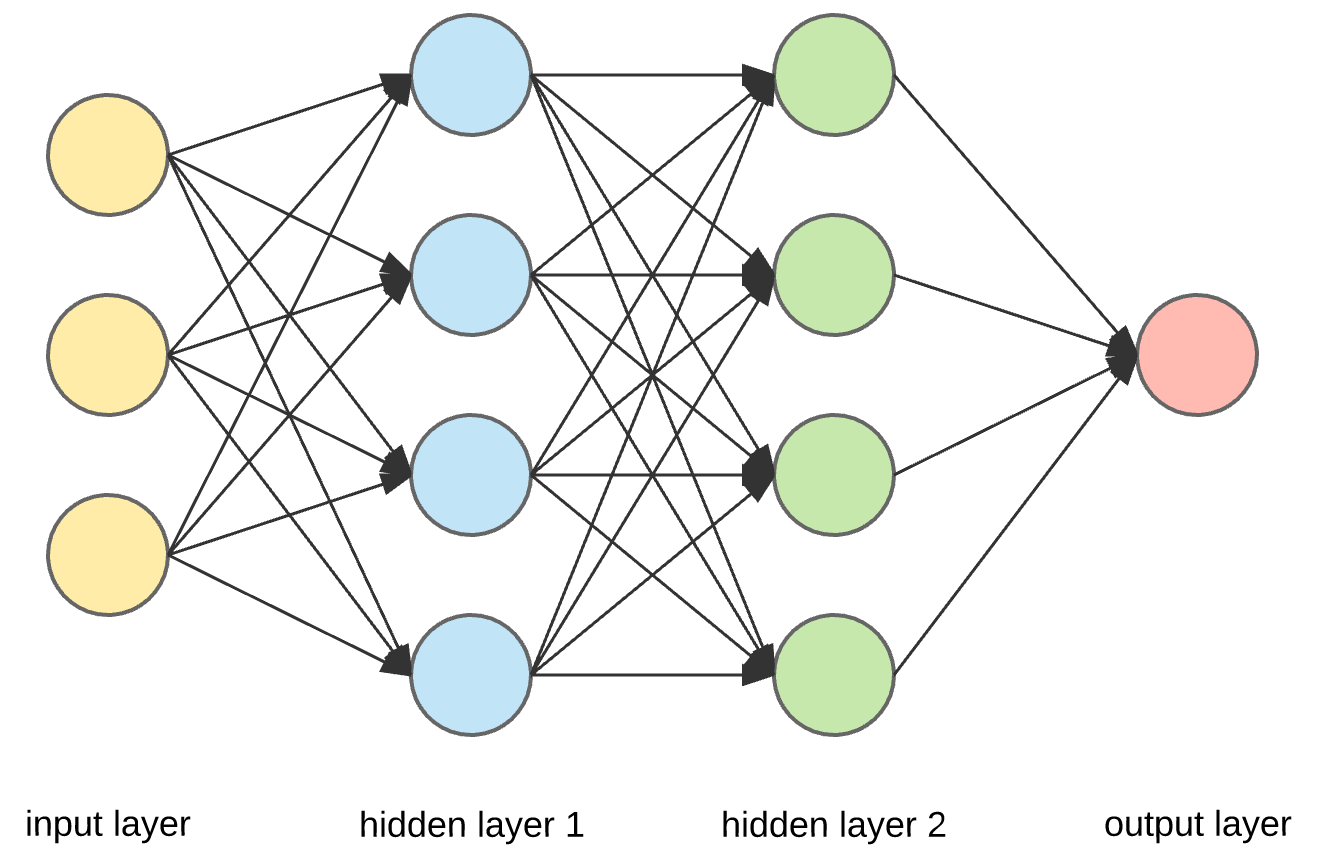
Pero, ¿cómo aprende esta red? A través de un proceso llamado ‘backpropagation’. Imagina lanzar una piedra a un estanque y observar las ondas. De manera similar, la red ajusta sus pesos en función de los errores de sus predicciones, refinando su ‘entendimiento’ con cada iteración.
En este proceso, las fórmulas juegan un papel crucial.
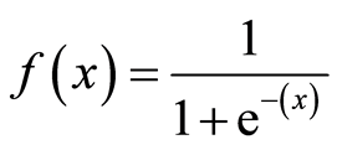
Por ejemplo, la función de activación sigmoide transforma los valores de entrada en un rango entre 0 y 1, lo que es ideal para procesos de clasificación binaria.
ReLU (Rectified Linear Unit) es particularmente popular en las capas ocultas de los sistemas neuronales profundas debido a su simplicidad y eficacia.
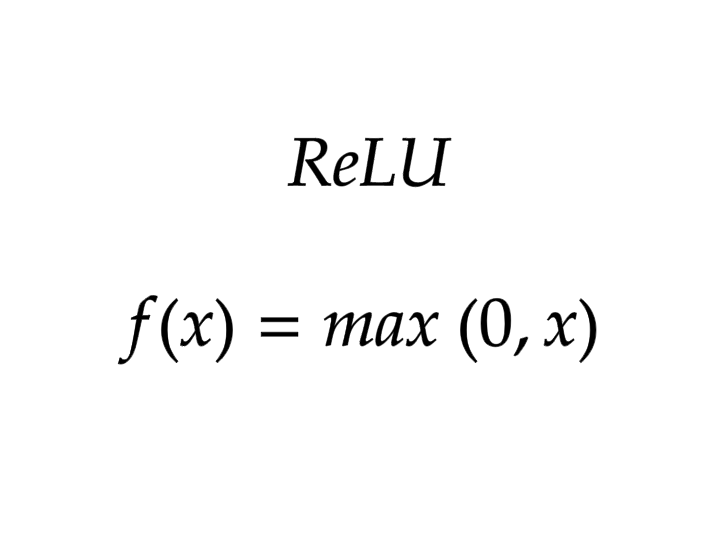
Lo que significa que si el valor de entrada x es positivo, la función devuelve ese mismo valor; si x es negativo, devuelve cero. Esta sencillez hace que la ReLU sea menos costosa computacionalmente y ayuda a mitigar el problema del gradiente desvaneciente en redes profundas, permitiendo que el modelo aprenda más rápido y de manera más efectiva.
Características de las redes neuronales
Redes neuronales no son solo un conjunto de algoritmos; son verdaderas obras de arte de la ingeniería y la ciencia de datos.
Independencia
Las redes poseen una capacidad asombrosa de independencia. No necesitan ser programadas con reglas específicas para cada tarea. En lugar de eso, aprenden de los datos que se les proporcionan, identificando patrones y tomando decisiones basadas en su ‘experiencia’. Esta independencia las hace increíblemente versátiles y adaptables a una amplia gama de aplicaciones.
Flexibilidad
La flexibilidad es otra característica clave. Pueden manejar y adaptarse a una variedad de situaciones y tipos de datos. Ya sea procesando enormes conjuntos de datos o ajustándose a nuevas formas de información, los sistemas neuronales muestran una capacidad asombrosa para ajustarse y evolucionar.
Aproximabilidad
La aproximabilidad se refiere a la habilidad de las redes para modelar cualquier función. No importa qué tan compleja sea la tarea, pueden aproximarse a la solución con una precisión sorprendente. Esta capacidad las convierte en herramientas poderosas para resolver problemas que antes eran inaccesibles para las computadoras.
Entrenamiento
Finalmente, el entrenamiento es el corazón de una red neuronal. A través de procesos como el aprendizaje supervisado o no supervisado, las redes neuronales ajustan sus ‘pesos’ internos para mejorar su rendimiento. Este proceso de aprendizaje continuo les permite mejorar con el tiempo, adaptándose a nuevas tareas y desafíos.
Errores de la red neuronal
Las redes, como cualquier otro sistema de aprendizaje, están sujetas a errores. Estos errores pueden deberse a varias razones, algunas de las cuales son inherentes a la naturaleza misma de las redes.
Desbalance de clases
Uno de los errores más comunes en los sistemas neuronales es el desbalance de clases. Esto ocurre cuando hay una gran disparidad en el número de muestras de diferentes clases dentro del conjunto de datos.
Por ejemplo, si una red está entrenada principalmente con datos de una clase, puede tener dificultades para reconocer y clasificar correctamente los datos de clases menos representadas. Esto puede llevar a una precisión engañosamente alta en la clase dominante, pero a un rendimiento pobre en las clases minoritarias.
Sobreajuste y subajuste
El sobreajuste es otro error común. Sucede cuando una red neuronal se entrena tanto con un conjunto de datos que comienza a aprender el ‘ruido’ en los datos en lugar de las tendencias subyacentes. Esto significa que aunque la red puede funcionar excepcionalmente bien en los datos de entrenamiento, su rendimiento en datos nuevos y no vistos es pobre.
Por otro lado, el subajuste ocurre cuando una red no se entrena lo suficiente. En este caso, la red no aprende las relaciones subyacentes en los datos, lo que resulta en un rendimiento deficiente tanto en los datos de entrenamiento como en los nuevos.
Errores en la corrección de datos
En el contexto de la memoria MLC NAND Flash, por ejemplo, los ingenieros han desarrollado sistemas basados en redes neuronales para mejorar la corrección de errores. Estos sistemas ayudan a detectar y corregir errores de bits, aumentando la fiabilidad de los datos almacenados. Sin embargo, incluso estos sistemas avanzados no son infalibles y pueden enfrentarse a desafíos debido a niveles altos de ruido que pueden degradar la información.
¿Cómo aprende una red neuronal?
Redes neuronales no nacen sabiendo todo; tienen que aprender, y lo hacen de una manera fascinante. Aquí te presento los principios básicos de cómo se entrenan las redes:
- Aprendizaje supervisado
En este enfoque, la red se entrena con un conjunto de datos que incluye las respuestas correctas. La red hace predicciones y luego ajusta sus parámetros internos basándose en la precisión de sus predicciones.
- Aprendizaje no supervisado
Aquí, la red intenta encontrar patrones y estructuras en los datos sin etiquetas predefinidas. Es como dejar que la red explore y descubra el mundo por sí misma.
- Retropropagación (Backpropagation)
Este es un método para ajustar los pesos de la red. Si la predicción de la red es incorrecta, el error se ‘propaga hacia atrás’, ajustando los pesos para mejorar las predicciones futuras.
- Función de pérdida
Un ejemplo clave es el error cuadrático medio red neuronal, esencial en el proceso de aprendizaje, esta función mide qué tan lejos están las predicciones de la red de los resultados reales. El objetivo es minimizar esta pérdida.
- Optimización y descenso de gradiente
La red utiliza algoritmos como el descenso de gradiente para cambiar sus pesos de manera que minimice la función de pérdida.
- Épocas de entrenamiento
Una época representa el umbral de una pasada completa a través del conjunto de datos de entrenamiento. Durante cada época, la red ajusta sus pesos para mejorar su rendimiento.
- Regularización y evitación del sobreajuste
Para evitar que la red aprenda demasiado de los datos de entrenamiento (sobreajuste), se utilizan técnicas de regularización que mantienen la red suficientemente generalista.
- Validación y pruebas
Después del entrenamiento, la red se prueba con nuevos datos para evaluar su rendimiento y generalización.
¿Qué es AI, ML, DL?
La Inteligencia Artificial (AI), el Aprendizaje Automático (ML) y el Aprendizaje Profundo (DL) pueden sonar como sacados de una película de ciencia ficción, pero son realidades tecnológicas que están transformando nuestro mundo. ¡Vamos a desglosarlos!
Inteligencia Artificial (AI)
La Inteligencia Artificial es como el gran paraguas bajo el cual se agrupan todas estas tecnologías. Es la capacidad de las máquinas para imitar la inteligencia humana. Piensa en un robot que puede resolver problemas o un software que puede tomar decisiones basadas en datos. La AI no solo se trata de robots; también incluye sistemas que pueden analizar datos, aprender de ellos y tomar decisiones inteligentes.
Aprendizaje Automático (ML)
El Aprendizaje Automático, a menudo programado en lenguajes como Python, es un subconjunto de la AI. Aquí es donde las máquinas no solo imitan la inteligencia humana, sino que también aprenden de los datos. Imagina un programa que puede mejorar su capacidad de reconocer patrones y hacer predicciones basadas en la experiencia previa, sin ser explícitamente programado para cada tarea. Es como enseñar a una máquina a aprender de sus errores y éxitos.
Aprendizaje Profundo (DL)
El Aprendizaje Profundo es un subconjunto más especializado del ML. Utiliza redes neuronales con muchas capas (de ahí lo de “profundo”) para aprender de grandes cantidades de datos. El DL es responsable de algunos de los avances más impresionantes en AI, como el reconocimiento de voz y de imágenes.
Dónde se utilizan las redes neuronales en el siglo XXI
Vamos a explorar algunos de los lugares más emocionantes donde las redes están dejando su huella.
En la medicina
Desde el diagnóstico de enfermedades hasta la personalización de tratamientos, estas redes están ayudando a los médicos a tomar decisiones más informadas. Imagina una red neuronal que puede analizar imágenes médicas y detectar anomalías con una precisión asombrosa, o que puede predecir la respuesta de un paciente a un tratamiento específico.
En el comercio y marketing
En el mundo del comercio, ejemplos de redes neuronales incluyen sistemas de recomendación personalizados, mostrando cómo estas tecnologías pueden ser aplicadas prácticamente. Piensa en cómo Netflix te sugiere películas o cómo Amazon te recomienda productos. Estas redes aprenden de tus preferencias y comportamientos para ofrecerte opciones que probablemente te encantarán.
En la seguridad y vigilancia
Las redes neuronales también están jugando un papel crucial en la seguridad. Desde el reconocimiento facial en aeropuertos hasta la detección de actividades sospechosas en videos de vigilancia, estas redes están ayudando a mantenernos más seguros.
En la automatización y robótica
En la industria, las redes están impulsando la próxima generación de robots y sistemas automatizados. Estos no son simplemente robots que realizan tareas repetitivas; son máquinas inteligentes que pueden destacar y aprender de su entorno para excel er en su rendimiento.
En el análisis de datos y predicciones
Finalmente, en el campo del análisis de datos, las redes neuronales están ayudando a descubrir patrones y tendencias ocultas en grandes conjuntos de datos. Desde predecir el clima hasta analizar tendencias del mercado, estas redes están ayudando a tomar decisiones basadas en datos más precisas y confiables.
Pensamientos finales
En conclusión, los sistemas neuronales representan una revolución en la forma en que interactuamos con la tecnología y comprendemos el mundo, abriendo un sinfín de posibilidades en campos tan diversos como la medicina, el comercio y la seguridad. Son, sin duda, una de las piedras angulares de la inteligencia artificial moderna, marcando el camino hacia un futuro más inteligente y conectado.
Aviso de responsabilidad
Este artículo se ofrece únicamente con propósitos informativos y educacionales. Ni el autor ni la plataforma asumen responsabilidad por las decisiones tomadas por los lectores basadas en su contenido. Se aconseja a los lectores llevar a cabo investigaciones independientes y buscar asesoramiento profesional antes de emprender acciones basadas en la información presentada aquí.
Preguntas frecuentes
¿Para qué sirven las redes neuronales?
Las redes sirven para modelar y resolver problemas complejos, imitando el funcionamiento del cerebro humano, en áreas como reconocimiento de patrones, procesamiento de datos y toma de decisiones.
¿Es Chat GPT una red neuronal?
Sí, Chat GPT es una red neuronal, específicamente un modelo de lenguaje basado en la arquitectura Transformer, diseñado para entender y generar texto de manera coherente y relevante.
¿Cuál es la diferencia entre IA y ML?
La Inteligencia Artificial (IA) es un campo amplio que abarca máquinas capaces de realizar tareas que requieren inteligencia humana, mientras que el Aprendizaje Automático (ML) es un subconjunto de IA que se enfoca en el aprendizaje y mejora a partir de los datos.
¿Cómo se aprenden las redes neuronales?
Las redes aprenden a través de procesos como el aprendizaje supervisado y no supervisado, ajustando sus pesos internos basados en la retroalimentación de su rendimiento en tareas específicas.
¿Qué tipo de problemas pueden resolver las redes neuronales?
Las redes neuronales pueden resolver una variedad de problemas, incluyendo reconocimiento de voz e imagen, predicciones financieras, diagnósticos médicos, y automatización de tareas complejas.
¿Cómo aprende una red neuronal?
Una red neuronal aprende ajustando sus pesos y sesgos internos en respuesta a los datos de entrenamiento, utilizando métodos como la retropropagación para mejorar su precisión en tareas específicas.
¿Cuáles son los distintos tipos de redes neuronales?
Existen varios tipos de redes neuronales, incluyendo redes neuronales convolucionales (para procesamiento de imágenes), redes recurrentes (para secuencias de datos), y redes de perceptrón multicapa (para clasificación y regresión).
¿Cuáles son las limitaciones de las redes neuronales?
Las limitaciones de las redes incluyen la necesidad de grandes cantidades de datos para el entrenamiento, la dificultad para interpretar su funcionamiento interno (caja negra), y la posibilidad de sobreajuste en datos limitados o sesgados.